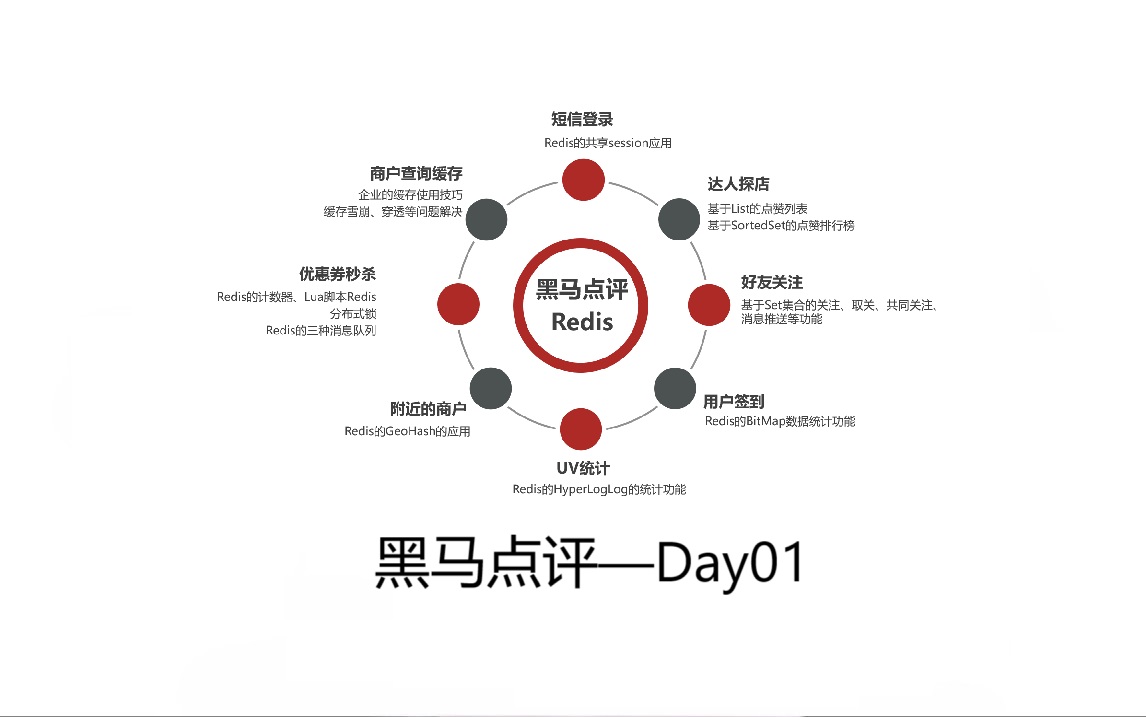
黑马点评项目总结
黑马点评项目总结
一、项目概述
黑马点评项目整体是前后端分离框架,前端采用 Vue 实现,后端基于 SpringBoot 构建单体服务,接入 Nginx 做反向代理、负载均衡与动静分离,MySQL 用来做数据持久化存储,Redis 作为核心组件,用于实现缓存、分布式锁、消息队列、高频数据存储等功能,核心解决本地生活场景下高并发访问、秒杀超卖、缓存异常等业务痛点。
二、核心业务流程
用户通过手机号验证码完成登录后,可实现附近商户查询、限时优惠券秒杀、探店笔记发布与点赞、博主关注与共同关注查看、每次签到与连续签到统计等核心功能,后端通过 Redis 的多种数据结构对高并发接口做全链路优化。保证服务在大流量场景下的可用性。
三、技术亮点与难点
3.1 Nginx 反向代理与负载均衡
Nginx 中的三层核心配置
- 第一是反向代理,将前端发起的
/api开头的后端请求转发到下游的 Tomcat 服务节点。 - 第二是负载均衡,配备了两个 Tomcat 服务节点,采用默认的轮询策略,将请求均匀分发到两个节点上,实现流量打散。
- 第三是动静分离,将前端的 Vue 打包文件、图片、JS/CSS 静态资源直接由 Nginx 托管,同时配置了本地缓存,不用转发到 Tomcat ,大幅降低后端压力。
做负载均衡的原因
- 分摊服务器压力,提升项目的整体并发承载能力。
- 做服务容灾,当其中一台 Tomcat 服务宕机,另一台还能正常承接用户请求,提升服务的整体可用性。
Nginx 的负载均衡策略
- 轮询(Round Robin):默认策略,依次将请求分发到每个服务器节点。
- 加权轮询(Weighted Round Robin):根据服务器节点的性能分配权重,性能更好的节点分配更多请求。
- IP 哈希(IP Hash):根据客户端IP地址进行哈希计算,将同一IP的请求分发到同一服务器节点,适用于需要会话保持的场景。
3.2 短信登录
基于 Session 实现登录
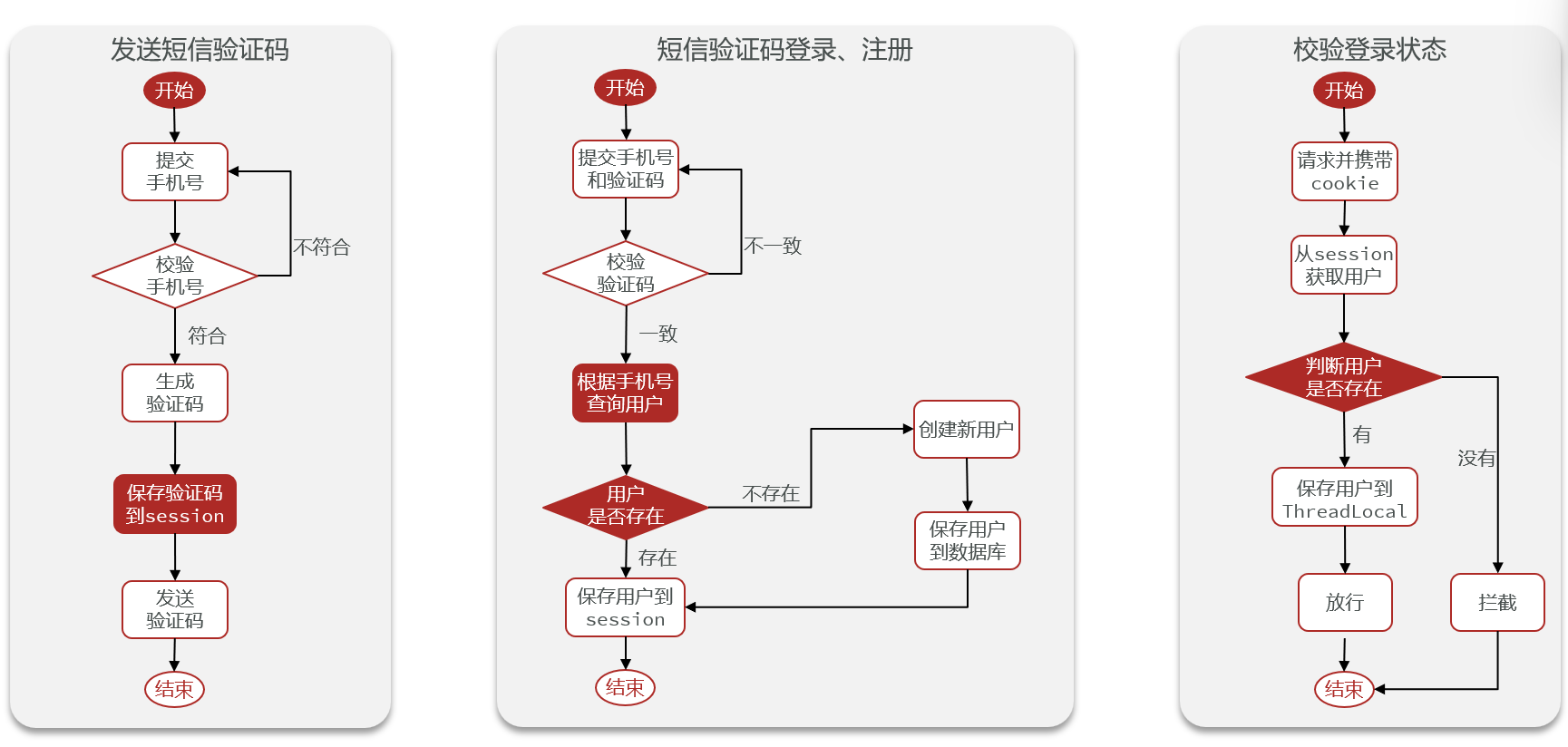
集群的 Session 共享问题
- Session 共享问题:多态Tomcat服务器不共享Session存储空间,当请求切换到不同tomcat服务器时会导致数据丢失。
- 解决方案:使用Redis来存储Session数据。
基于Redis实现共享Session登录
-
之前使用Session时由于每个请求都有独立的Session空间,所以保存验证码时key使用
code字段即可,但在使用Redis存储Session时,key需要包含用户的唯一标识以区分不同用户的Session。 -
用户登录成功后,使用UUID生成一个随机
token作为key值存放到Redis中,value为用户信息,同时设置30分钟的过期时间。
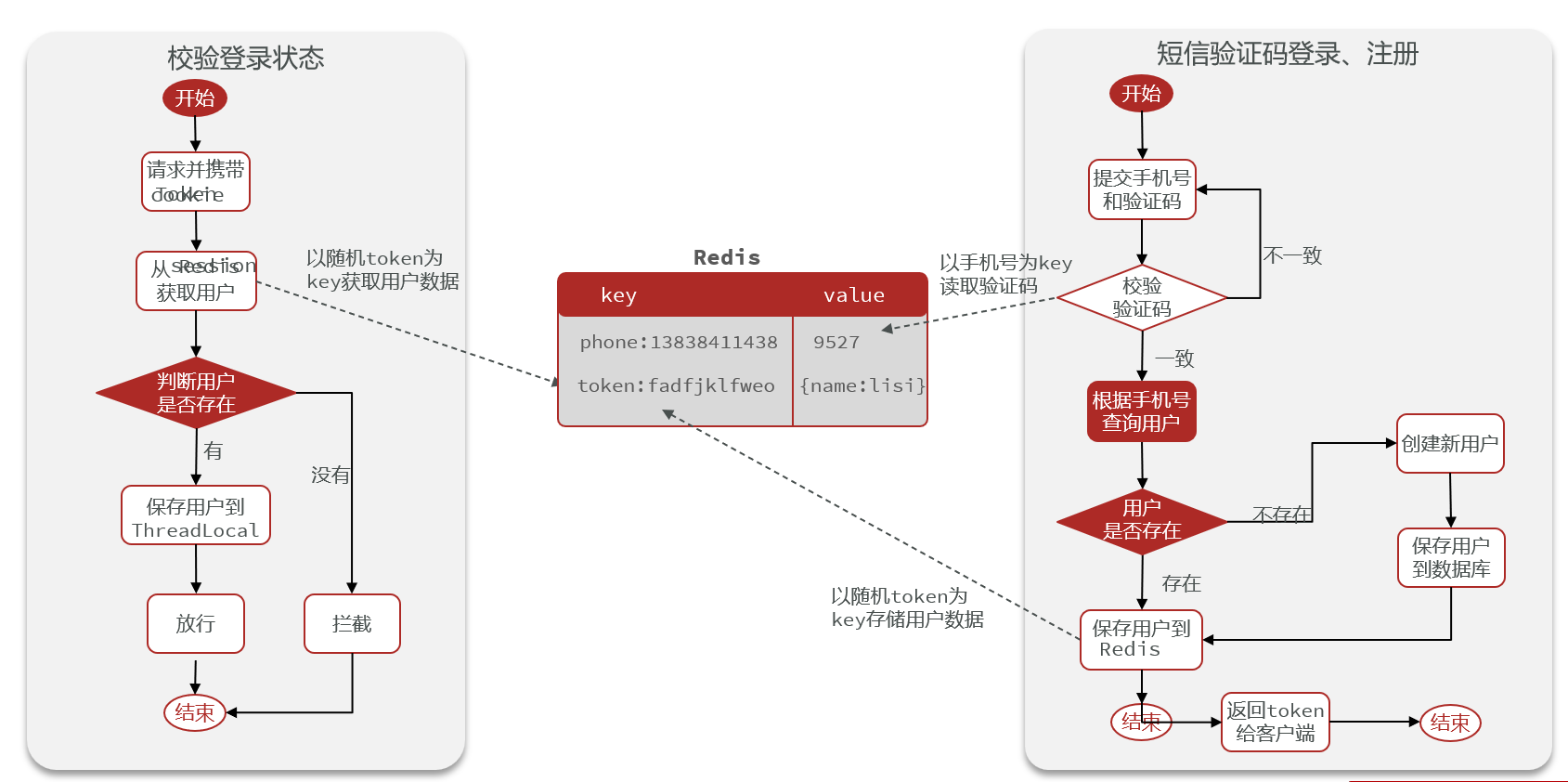
-
还有没有其他的解决方法:
- 基于Cookie的Token机制,不再使用服务端保存Session,而是通过客户端保存Token(如JWT)。
- Token中包含用户的认证信息(如用户ID、权限等),并通过签名验证其完整性和真实性。
- 每次请求,客户端将Token放在Cookie或HTTP头中发送到服务
双层拦截器设计解决登录状态刷新问题
- 设计第一个拦截器的原因:当Session请求变多时,每一个Session都要单独进行校验,浪费资源,所以使用拦截器进行校验。
- 单拦截器存在的问题:只有访问拦截器需要拦截的接口时才会刷新token有效期,如果访问其他窗口则不会刷新,导致用户登录失效。
- 解决方法:设置双拦截器
- 第一个拦截器:拦截一切路径,获取token并去查询用户信息,查到了就存入ThreadLocal的UserHolder中,同时刷新token有效期。不论是否查到用户,都放行。
- 第二个拦截器:只拦截需要登录状态的接口,判断ThreadLocal中的用户是否存在。
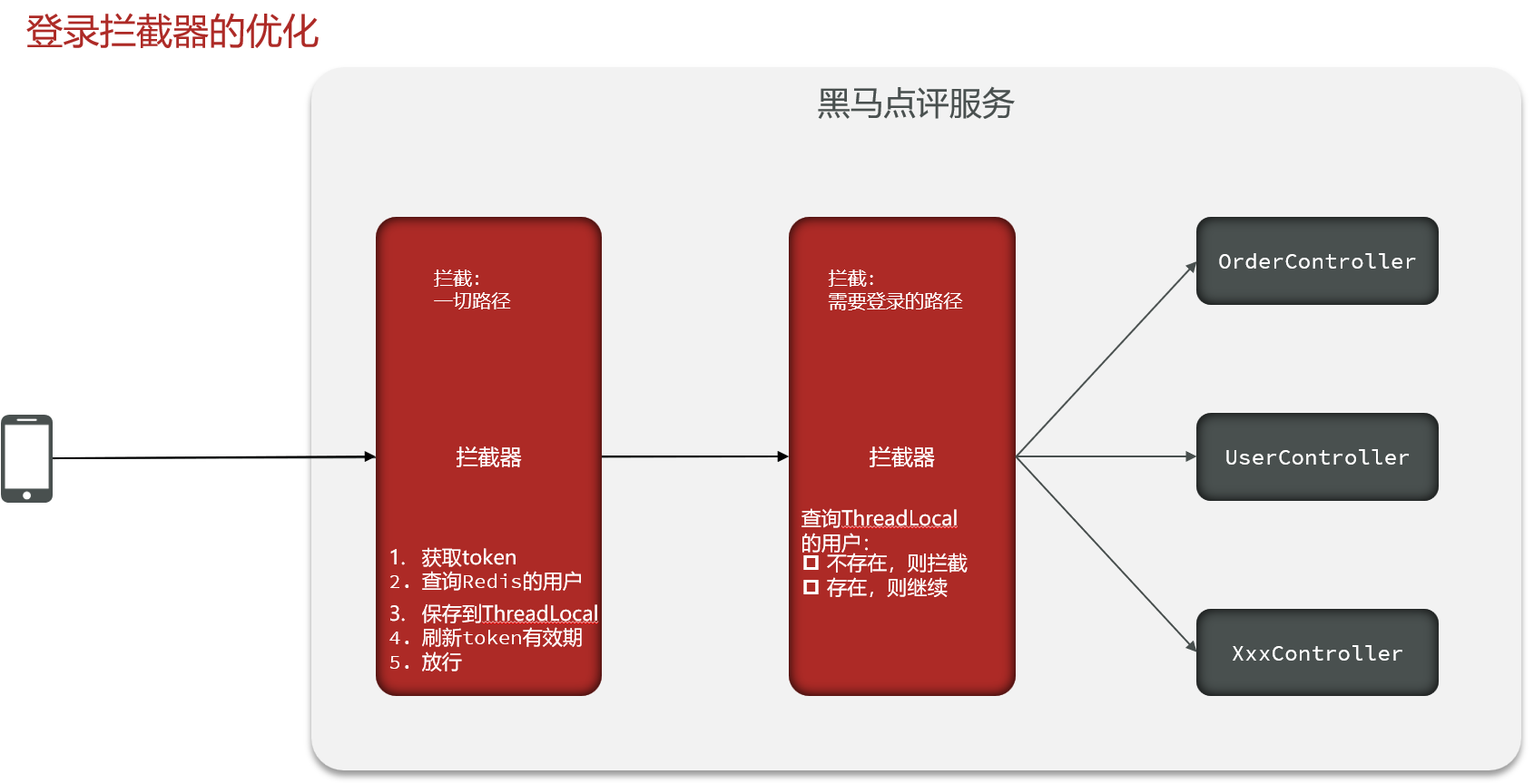
拦截器+ThreadLocal做登录校验和权限刷新
- 拦截器执行流程,拦截器按
order优先级执行:- 第一层
RefreshTokenInterceptor:在所有Controller方法执行前,先执行preHandle方法:从请求header里获取token,去Redis查询用户信息,查到了就存入ThreadLocal,同时刷新token有效期,始终返回true放行;请求完全结束后,会执行afterCompletion方法,移除ThreadLocal里的用户信息。 - 第二层
LoginInterceptor,在RefreshTokenInterceptor之后执行,preHandle方法里只做一件事:判断ThreadLocal里是否有用户信息,没有就返回401状态码拦截请求,有就返回true放行,执行后续的Controller方法。
- 第一层
- SpringMVC拦截器完整的执行链路:preHandle(请求前) -> Controller方法 -> postHandle(请求后) -> afterCompletion(请求完全结束后)。
ThreadLocal的作用:ThreadLocal为每个线程提供独立的变量副本,保证在多线程环境下数据的隔离性和安全性。在本项目中,ThreadLocal用于存储当前请求的用户信息,确保每个请求线程都能独立访问和修改自己的用户数据,避免了多线程环境下的数据冲突和安全问题。- 注意:
ThreadLocal必须在请求完全结束后使用remove方法手动清除,否则可能会导致内存泄漏问题。
3.3 商户查询缓存
标准的查询缓存流程
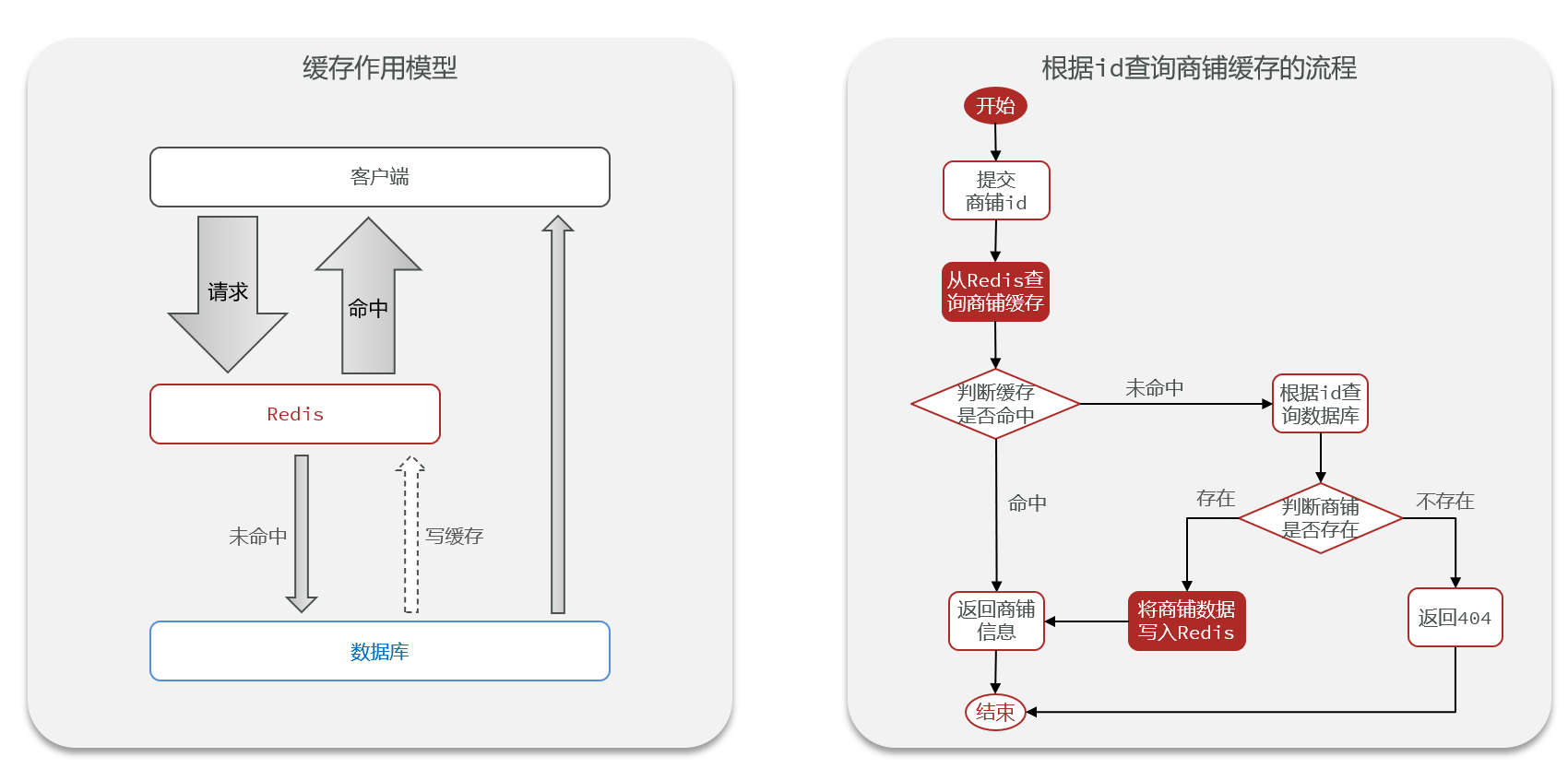
缓存相关问题
- 缓存穿透
- 缓存击穿
- 缓存雪崩
解决缓存穿透问题
- 缓存穿透问题是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
- 解决方案:
- 缓存空值:对数据库查询为空的结果,作缓存空值处理,设置2分钟的短过期时间,防止同一个无效ID重复打库。
- 布隆过滤器:布隆过滤器底层使用位数组+多个布隆hash函数,可以判断一个元素是否存在于集合中。
- 如果布隆过滤器判断元素不存在,则一定不存在,直接返回错误响应。
- 如果布隆过滤器判断元素存在,则可能存在,需要继续查询数据库验证。
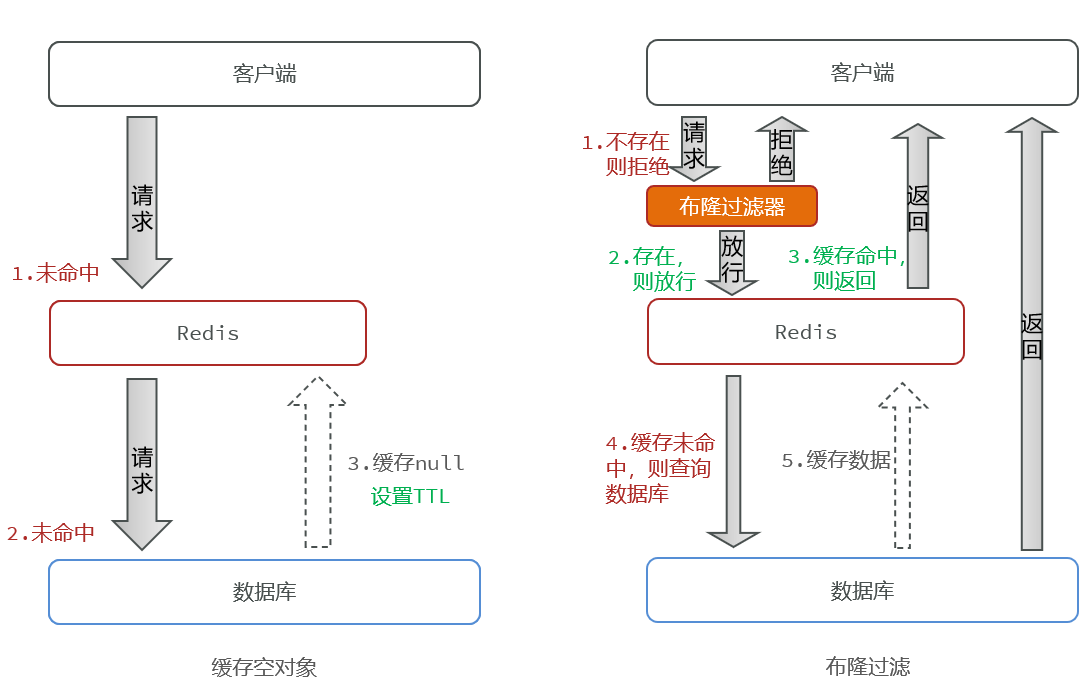
解决缓存击穿问题
- 缓存击穿问题是指某个热点key在缓存中突然过期,短时间内大量请求同时打到数据库,造成数据库压力过大。
- 解决方案:
- Redis互斥锁:对普通热点key,当缓存未命中时,只有拿到锁的一个线程能去查库重建缓存,其他线程自旋等待重试。
- 逻辑过期:对超高并发的秒杀热点key,缓存中不设置物理过期时间,而是在value中存一个逻辑过期时间,用户请求时发现数据逻辑过期,就获取锁开启独立线程异步重建缓存,当前线程直接返回旧的缓存数据,用户请求永远只走缓存。
- 互斥锁实现简单,能保证数据强一致性,适合对数据一致性要求高的普通业务场景;逻辑过期实现复杂,性能高,适合秒杀这种对服务可用性要求高于一致性的高并发业务。
解决缓存雪崩问题
- 缓存雪崩问题是指大量key在同一时间过期,或者Redis服务宕机,导致大量请求同时打到数据库,造成数据库压力过大。
- 解决方案:
- 随机过期时间:给缓存key设置一个随机的过期时间,避免大量key在同一时间过期。
- 双层缓存:在Redis前面再加一层本地缓存,先查询本地缓存,命中则直接返回,未命中再查询Redis,减少对Redis的压力。
- Redis集群:使用Redis集群部署,提升Redis的整体可用性和抗压能力。
3.4 优惠券秒杀
优惠券秒杀下单流程
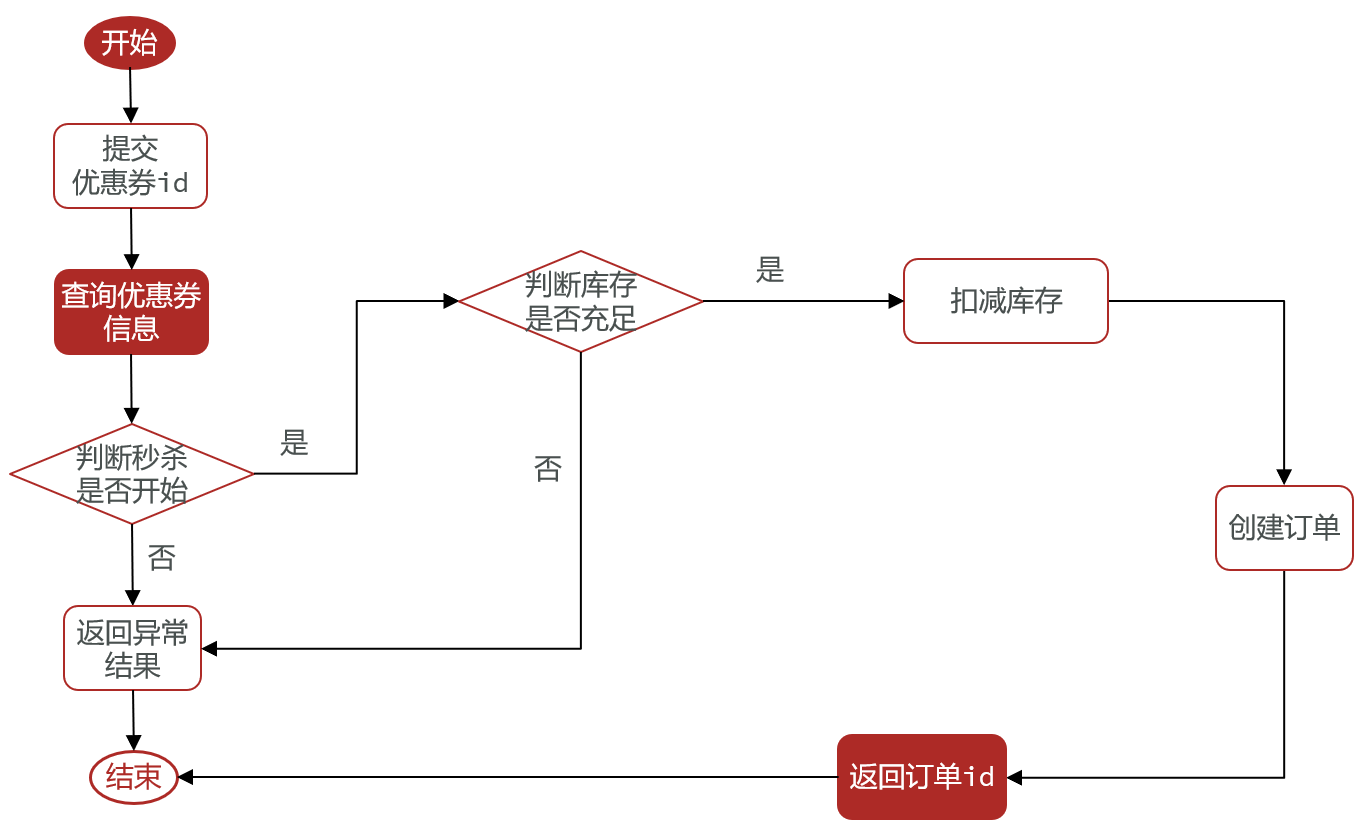
秒杀中的问题
- 超卖问题
- 一人一单的线程安全问题
全局唯一ID
用户抢购时会生成订单并保存到tb_voucher_order表中,而订单表如果使用数据库自增id就会存在一些问题:
- id规律太明显:用户或者商业对手容易根据id猜测出一些敏感信息
- 受单表数据量限制:当订单表数据量过大时,可能会进行分库分表,这时就需要保证id的唯一性
全局唯一ID生成策略
- UUID
- Redis自增
- Snowflake算法(雪花算法):1位符号位 + 41位时间戳 + 10位机器id + 12位序列号
- 数据库自增
- 项目中使用:1位符号位 + 31位时间戳 + 32位序列号
乐观锁解决超卖问题
超卖问题
在高并发请求下,多个用户同时抢购同一商品可能会导致库存不足的情况。简单来说就是:判断库存是否充足操作和扣减库存操作不是原子性的,可能会出现多个线程同时判断库存充足并扣减库存,最终导致超卖。
常见解决方法
- 悲观锁:如
synchronized、lock - 乐观锁:如版本号法、CAS操作
CAS(Compare and Swap)算法介绍
CAS操作是一个原子操作,可以保证线程安全。它包含三个参数:内存地址V、旧的预期值A、新值B。CAS执行过程如下:
- 比较:比较地址V中的值与预期值A是否相等
- 判断:相等则说明没有发生其他线程的修改
- 交换:将地址V中的值更新为新值B
- CAS问题:
- ABA问题:如果一个线程在执行CAS操作时,另一个线程修改了值又改回原值,CAS操作会误以为没有发生修改,导致数据不一致。解决方法:引入版本号或标记位等机制。
- 自旋问题:当CAS操作失败时,线程会不断重试,可能会导致CPU资源浪费。解决方法:设置重试次数或使用适当的等待策略。
- 只能保证一个变量的原子操作:CAS只能保证单个变量的原子操作,如果需要对多个变量进行原子操作,可能需要使用其他同步机制,如锁。
项目实现
在扣减库存时,在update语句的where条件中加了stock>0的判断,也就是.setSql(“stock = stock - 1”).eq(“voucher_id”, voucherId).gt(“stock”, 0),只有库存大于0时,扣减才会生效,本质是无锁化的CAS思想,对比库存是否满足条件,满足才执行更新。
- 优点:实现简单,无锁的开销,没有死锁风险。
- 缺点:高并发下冲突率极高,大量请求扣减失败,秒杀成功率极低,而且所有请求都直接打到数据库,会给数据库造成极大的压力,只能用于低并发场景。
分布式锁解决一人一单问题
一人一单问题
- 在高并发请求下,可能会出现同一个用户同时发起多个抢购请求,导致生成多条订单记录。
- 解决方法:乐观锁比较适合更新操作,而现在是插入操作,不方便实用乐观锁,所以使用悲观锁。
项目中使用
- 最开始使用synchronized锁,但是发现加锁只能解决单机环境下的一人一单安全问题,集群模式下就不行了。
- 原因:synchronized是jvm层面的锁,而我们部署了多个tomcat服务器,每个tomcat都有一个属于自己的jvm,所以在不同的tomcat内部锁的对象不一样,导致synchronized锁失效。
- 解决方案:使用分布式锁。
分布式锁解决一人一单问题
- 首先使用Redis的
set nx实现分布式锁:获取锁 -> 互斥访问,释放锁 -> 手动释放或超时释放。- 存在的问题:锁误删问题:当线程1阻塞时会释放锁,这时线程2获取锁成功,线程1恢复后继续执行删除任务,导致线程2的锁被误删
- 解决方法:给锁添加标识,只有持有锁的线程才能释放锁
- 在获取锁时存入线程标识
- 在释放锁时先获取锁中的线程标识,判断是否与当前线程标识一致,一致才执行删除操作
- 依旧存在的问题:判断锁归属和删除锁不是原子操作,仍然可能存在误删问题
- 解决方法:Lua脚本解决锁误删问题
- 使用Lua脚本,将判断锁是否属于当前线程 + 删除锁操作写在一个脚本里,彻底解决原子性问题。
- 基于
set nx实现的分布式锁存在的问题:- 不可重入:同一个线程无法多次获取同一把锁
- 不可重试:获取锁只尝试一次就返回false,没有重试机制
- 超时释放:锁超时释放虽然可以避免死锁,但如果是业务执行耗时较长,也会导致锁释放,存在安全隐患
- 主从一致性:如果Redis提供了主从集群,主从同步存在延迟,当主宕机时,如果从并同步主中的锁数据,则会出现锁实现
- 解决方法:使用Redission分布式锁。
- 基于
- 引入Redission分布式锁,解决锁的可重入、自动续期、重试等复杂问题,完美适配秒杀场景的并发需求。
整体流程梳理
synchronized锁存在集群问题 -> 基于Redis的set nx实现分布式锁 -> 利用线程标识解决所误删问题 -> 使用Lua脚本实现原子性操作彻底解决所误删问题 -> 引入Redission分布式锁解决锁的可重入、重试、自动续期等问题。
3.5 秒杀优化
秒杀优化整体流程
- 原流程存在的问题:查询优惠卷、查询订单、减库存以及创建订单这四个步骤都需要访问数据库,所以耗时比较高,而我们又是串行执行的这几个步骤,所以在高并发情况下效果会比较差
- 解决方法:将耗时比较短的逻辑判断放入到redis中,比如是否库存足够,比如是否一人一单,这样的操作,只要这种逻辑可以完成,就意味着我们是一定可以下单完成的,我们只需要进行快速的逻辑判断,然后将真正的下单操作放到异步线程中去执行即可
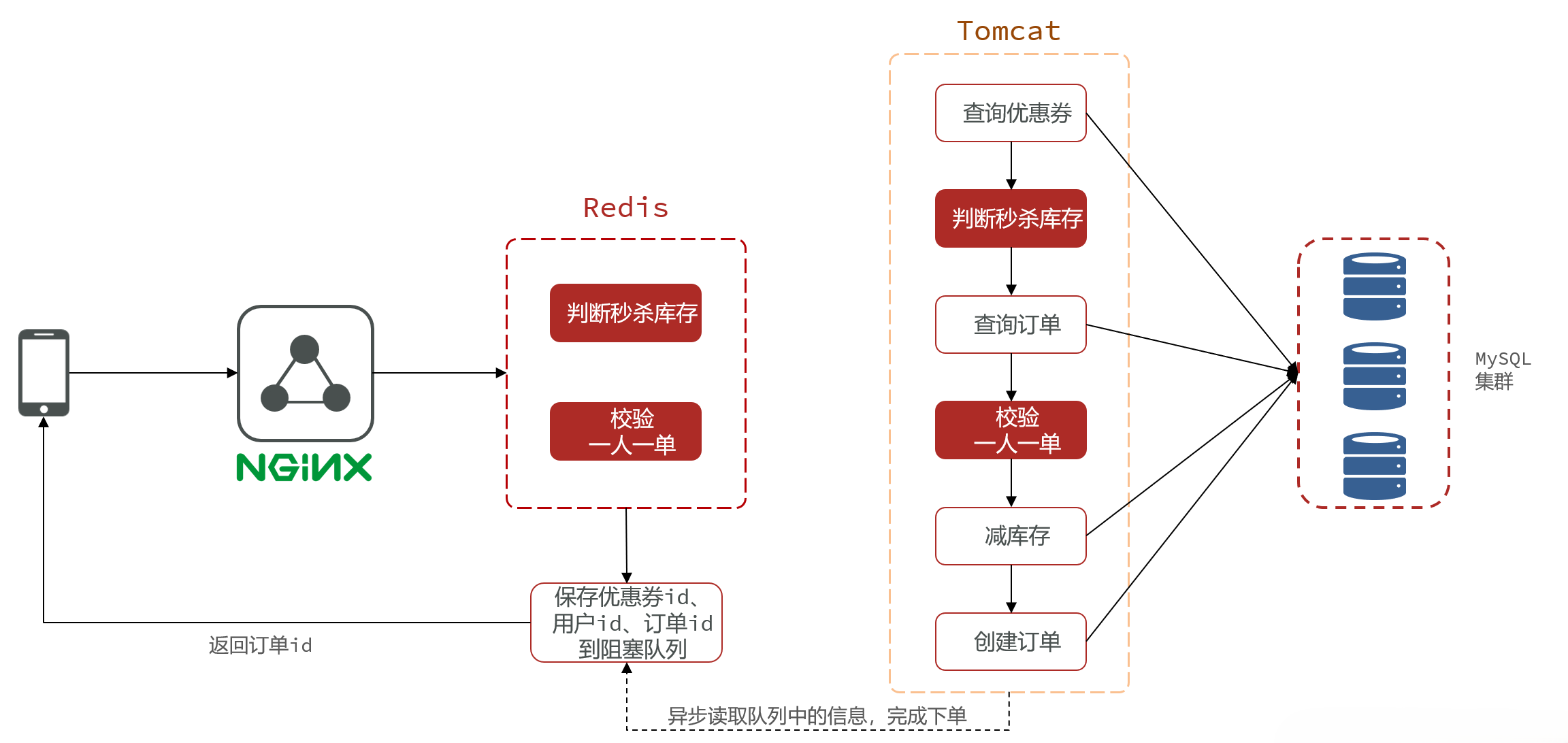
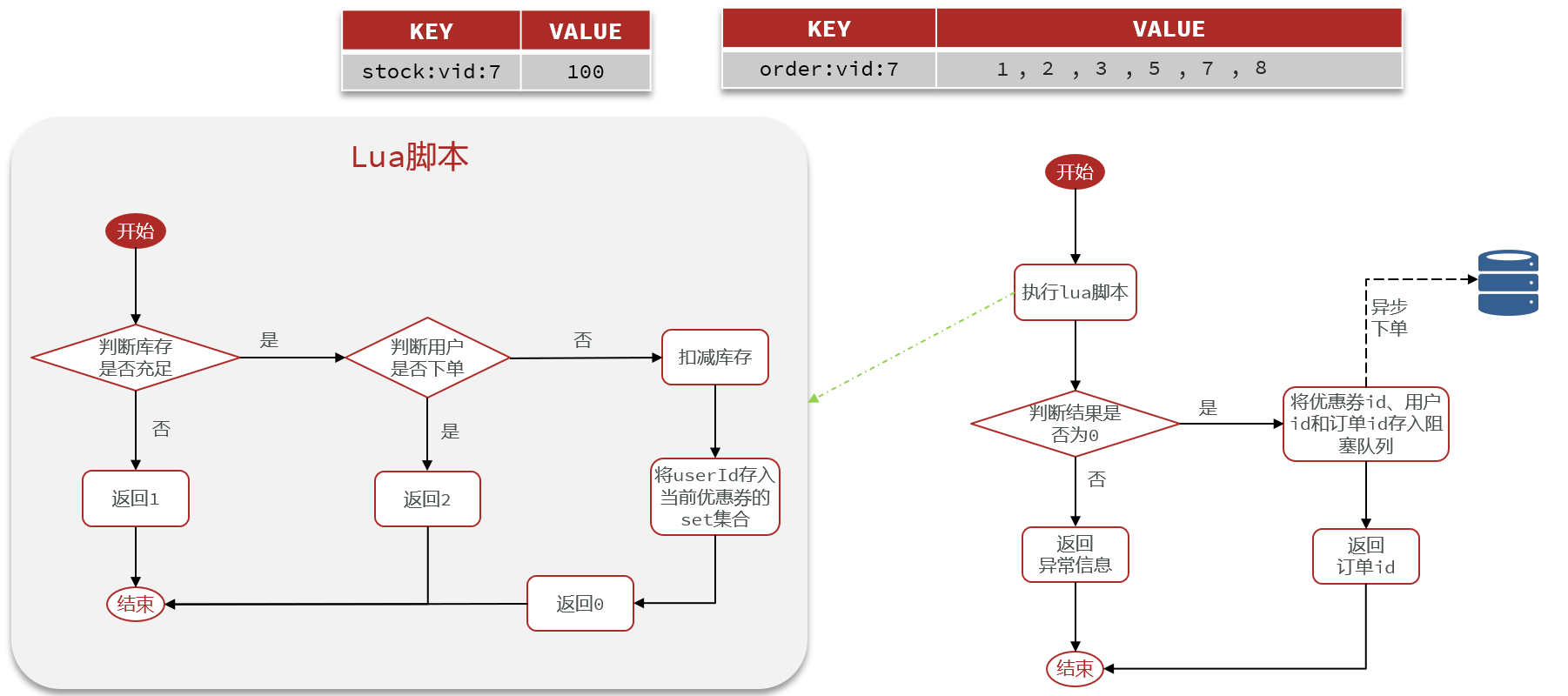
Redis Stream消息队列
消息队列模型包含三个角色
- 消息队列:存储和管理消息,也称消息代理
- 生产者:发送消息到消息队列
- 消费者:从消息队列接收和处理消息
Redis提供了三种不同的方式实现消息队列
- list结构:基于List结构模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
- 详见Redis的三种消息队列实现方式
为什么选择使用Stream
- List结构:只能用LPUSH+BRPOP实现简单的消息队列,优点是实现简单,支持阻塞读取,但是消息消费完就会被删除,不支持消息回溯、不支持消费者组,消费者宕机就会丢失消息,也无法实现多消费者负载均衡。
- PubSub发布订阅模式:支持多生产多消费,但是消息是发布即忘的,不支持持久化,消费者离线就会丢失所有消息,也没有消息确认机制,消息丢失风险极高,完全不适合秒杀订单这种不能丢的场景。
- Stream结构:是Redis 5.0引入的专门的消息队列结构,支持消息持久化、消息回溯、消费者组模式,自带ACK消息确认机制和pending-list,消费者处理完消息后执行XACK确认,未确认的消息会进入pending-list,故障恢复后可以重新处理,保证消息至少被消费一次,不会丢失,同时支持多消费者争抢消息,实现负载均衡,完美匹配秒杀订单的场景需求。
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞队列 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
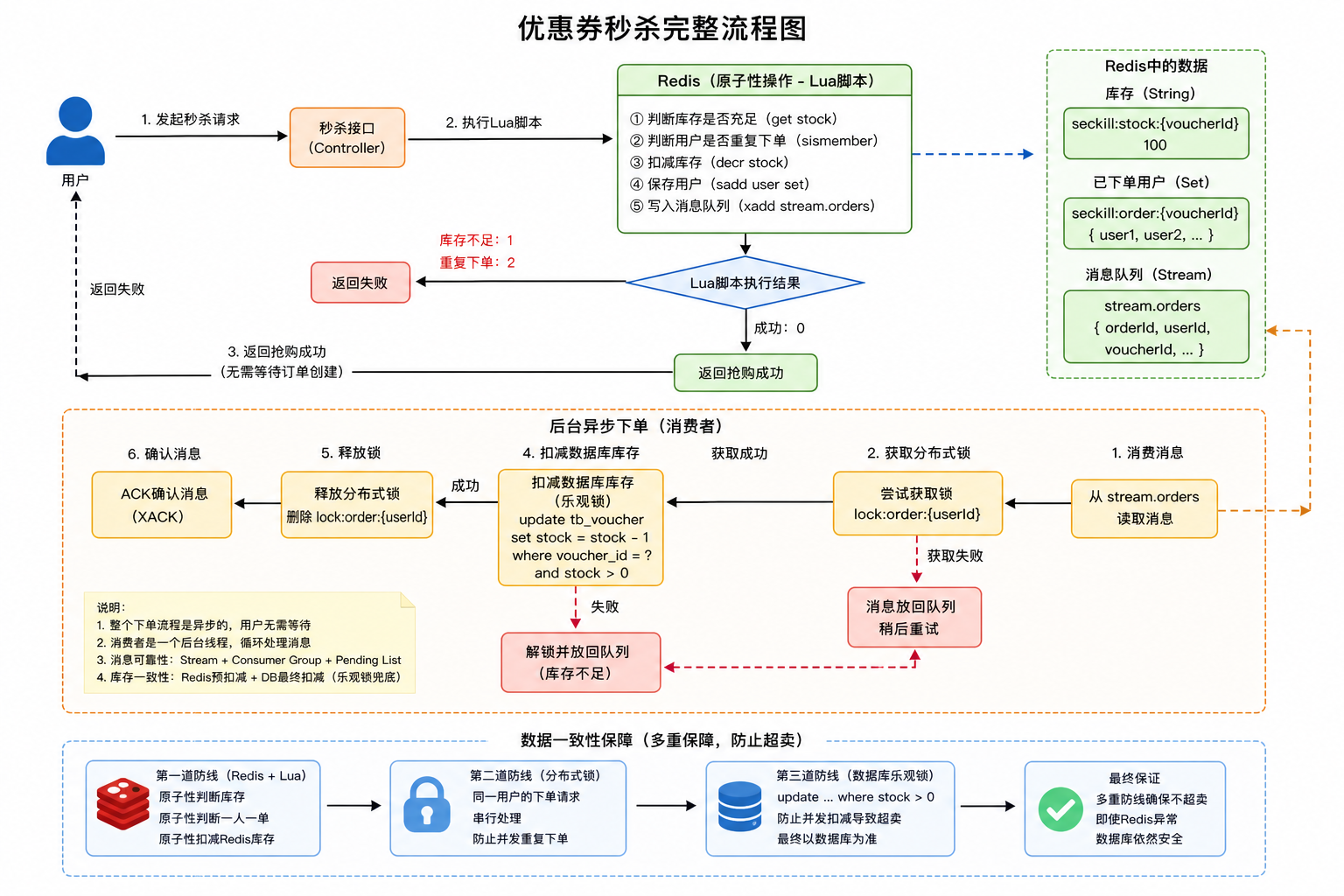
⭐秒杀最终方案
最终在项目中,我采用的是 Redis + Lua + Stream + Redisson 的高并发秒杀方案。
用户发起秒杀请求后,会先执行 Lua 脚本,在 Redis 中原子性完成库存校验、一人一单校验、库存预扣减以及订单消息入队操作,并快速返回秒杀结果,避免请求直接打到数据库。
之后由异步线程消费 Redis Stream 中的订单消息,完成数据库订单创建和库存扣减。为了避免消息重复消费导致重复下单,在订单创建阶段又通过 Redisson 分布式锁进行并发控制,同时数据库层使用 CAS 乐观锁作为最终防超卖兜底。
整个方案通过 Redis 承担高并发流量、MQ 异步削峰、分布式锁保证幂等性、数据库乐观锁保证最终一致性,大幅降低了数据库压力,并提升了秒杀场景下的系统吞吐能力和稳定性。
lua 脚本(seckill.lua)核心逻辑:
1 | -- 1. 参数列表 |
面试中如果问到:你做这个项目遇到的那些难点/你觉得你做得好的点是哪里,可以这样回答:
在这个项目中,我觉得做得比较好的一个点是优惠券秒杀模块的高并发优化设计。
一开始我们是基于数据库同步下单的方案,在高并发场景下会出现数据库压力过大、响应慢,以及一人多单等问题。后面我重点对这一块做了优化,核心目标是提升系统在高并发下的吞吐能力,同时保证库存不超卖和订单不重复。
我的整体思路是把请求尽量前置到 Redis 层处理,而不是直接打到数据库。具体来说,用户发起秒杀请求后,会先通过 Lua 脚本在 Redis 中完成库存校验、一人一单校验以及库存预扣减,并把订单信息写入 Stream 队列,这一步是原子执行的,可以保证并发安全,同时也能快速返回结果给用户。
之后通过异步线程消费 Stream 中的消息,在数据库中完成订单创建和库存扣减。考虑到消息队列存在重复消费的可能,我在消费者侧引入了 Redisson 分布式锁来保证同一个用户的订单创建过程串行执行,同时在数据库层使用乐观锁作为最终兜底,避免极端情况下出现超卖问题。
通过这一套方案,把绝大部分请求都拦在了 Redis 层,数据库只负责最终的数据落库,大幅降低了数据库压力,同时也提升了系统的整体吞吐能力和稳定性。
3.6 点赞与点赞排行
ZSet实现点赞功能
ZSet设计
- key:
blog:liked:{笔记ID} - value:点赞用户ID
- score:点赞时间戳。
- 用时间戳作为score既能保证用户ID的唯一性,又能记录点赞的先后顺序,实现按点赞时间排序的排行榜。
需求
- 同一个用户只能点赞一次,再次点击则取消点赞
- 如果当前用于已经点赞,则点赞按钮高亮显示
实现
- 点赞时,使用
ZADD key 时间戳 用户ID命令,把用户ID加入ZSet,同时给数据库中的笔记点赞数+1 - 取消点赞时,使用
ZREM key 用户ID命令,把用户ID从ZSet中移除,同时给数据库中的笔记点赞数-1 - 判断用户是否已经点赞,使用
ZSCORE key 用户ID命令,如果返回非null则说明已经点赞,返回null则说明未点赞
排行榜实现
- 需求:展示给笔记点赞的前5位用户,形成点赞排行
- 实现:使用
ZRANGE key 0 4命令,获取ZSet中score最高的前5个用户ID,再根据ID列表查询用户信息,用ORDER BY FIELD(id,...)保持原有顺序展示在前端。
3.7 关注与共同关注
Set实现关注功能
Set设计
- key:
follows:{用户ID} - value:被关注用户ID
- Set集合还自带去重能力,关注/取关用
SADD/SREM命令,都是O(1)时间复杂度,操作性能极高,完全适配关注场景的高频操作
共同关注
- 使用
SINTER follows:{当前用户ID} follows:{目标用户ID}命令,获取两个用户的关注集合的交集,即共同关注的用户ID列表。
3.8 附近商铺查询
Redis GEO实现附近商户查询
Redis GEO是Redis 3.2版本引入的地理空间数据结构,专门用来存储和查询经纬度坐标数据,我在项目里的具体实现是:
- 数据预热:项目启动时,把数据库里的所有商户,按商户类型分组,同类型的商户用GEOADD命令,把商户ID、经度、纬度存入同一个GEO集合,Key设计为shop:geo:{类型ID}
- 附近商户查询:用户查询指定类型的附近商户时,获取用户当前的经纬度,用GEOSEARCH命令,以用户坐标为圆心,指定5公里为半径,查询范围内的商户ID,同时返回商户和用户的距离
- 结果处理:拿到商户ID列表后,根据ID查询商户详情,把距离设置到商户信息里,按距离排序后返回给前端
Redis GEO底层原理
- Redis GEO的底层是用
SortedSet实现的,核心采用Geohash算法,把经度和纬度的二维坐标,通过区间二分编码,转换成一个一维的52位整数字符串,然后把这个字符串作为SortedSet的score值。这样就能通过score的范围查询,找到地理空间上距离相近的元素,也就是附近的商户,同时还能通过Geohash编码计算两个坐标之间的距离。
3.9 用户签到与UV统计
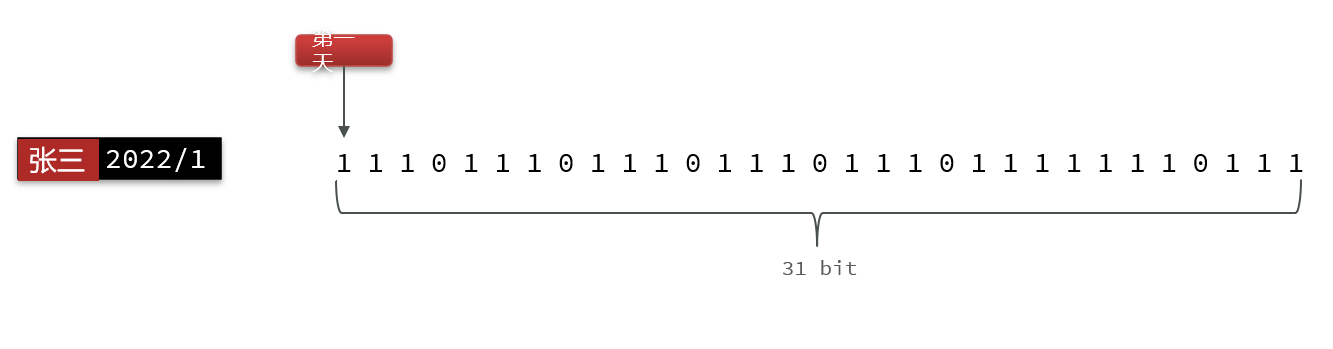
Bitmap实现用户签到
把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0
HyperLogLog实现UV统计
UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:HyperLogLog 算法的原理讲解以及 Redis 是如何应用它的
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
四、数据库表设计
该项目中比较重要的表:
- tb_user(用户表)
- tb_user_info(用户详情表)
- tb_shop(店铺表)
- tb_shop_type(店铺类型表)
- tb_voucher(优惠券表)
- tb_seckill_voucher(秒杀券表)
- tb_voucher_order(订单表)
- tb_blog(笔记表)
- tb_follow(关注表)
整体可以分为 4 类:用户、店铺、优惠券、社交互动
4.1 用户相关表
4.1.1 tb_user(用户表)
| 字段 | 含义 |
|---|---|
| id | 用户ID(主键) |
| phone | 手机号 |
| password | 密码(可为空,短信登录) |
| nick_name | 昵称 |
| icon | 头像 |
| create_time | 创建时间 |
| update_time | 更新时间 |
👉 特点:
- 支持短信验证码登录
- password 在项目中基本不用
4.1.2 tb_user_info(用户详情表)
| 字段 | 含义 |
|---|---|
| user_id | 用户ID |
| city | 城市 |
| introduce | 个人介绍 |
| fans | 粉丝数 |
| follow | 关注数 |
👉 拆表原因:冷热数据分离
4.2 店铺相关表
4.2.1 tb_shop(店铺表)
| 字段 | 含义 |
|---|---|
| id | 店铺ID |
| name | 店铺名称 |
| type_id | 店铺类型 |
| address | 地址 |
| x / y | 经度 / 纬度 |
| avg_price | 人均消费 |
| sold | 销量 |
| comments | 评论数 |
| score | 评分 |
👉 核心点:
- 用于 附近商户查询(Geo)
- 高并发读热点数据
4.2.2 tb_shop_type(店铺类型表)
| 字段 | 含义 |
|---|---|
| id | 类型ID |
| name | 类型名称 |
| icon | 图标 |
| sort | 排序 |
4.3 优惠券 / 秒杀
4.3.1 tb_voucher(优惠券表)
| 字段 | 含义 |
|---|---|
| id | 优惠券ID |
| shop_id | 店铺ID |
| title | 标题 |
| sub_title | 副标题 |
| pay_value | 支付金额 |
| actual_value | 抵扣金额 |
| type | 普通 / 秒杀 |
4.3.2 tb_seckill_voucher(秒杀券表)
| 字段 | 含义 |
|---|---|
| voucher_id | 优惠券ID |
| stock | 库存 |
| begin_time | 开始时间 |
| end_time | 结束时间 |
👉 分表原因:
- 秒杀数据访问频繁
- 减少主表压力
4.3.3 tb_voucher_order(订单表)
| 字段 | 含义 |
|---|---|
| id | 订单ID |
| user_id | 用户ID |
| voucher_id | 优惠券ID |
| pay_type | 支付方式 |
| status | 状态 |
| create_time | 创建时间 |
👉 核心点:
- 实现一人一单
- 配合 Redis + Lua 保证原子性
4.4 社交互动
4.4.1 tb_blog(笔记表)
| 字段 | 含义 |
|---|---|
| id | 笔记ID |
| user_id | 作者 |
| title | 标题 |
| content | 内容 |
| liked | 点赞数 |
| comments | 评论数 |
4.4.2 tb_follow(关注表)
| 字段 | 含义 |
|---|---|
| user_id | 用户 |
| follow_user_id | 被关注用户 |
五、Redis 设计(重点🔥)
Redis 在这个项目中是性能核心,主要用于:
- 缓存
- 分布式锁
- 秒杀
- 社交 Feed 流
5.1 登录 & Token
key 设计:
1 | login:code:{phone} -> 验证码 |
value:
- Hash结构(用户信息)
👉 特点:
- 替代 Session(无状态登录)
- TTL 控制登录过期
5.2 店铺缓存
key:
1 | cache:shop:{id} |
value:
- JSON(店铺对象)
👉 设计点:
- 缓存穿透 → 空值缓存
- 缓存击穿 → 互斥锁 / 逻辑过期
- 缓存雪崩 → TTL 随机化
5.3 店铺类型缓存
1 | cache:shop:type |
👉 List结构(有序)
5.4 Geo 地理位置
key:
1 | shop:geo:{typeId} |
value:
- GEO结构(Redis)
👉 存储:
1 | shopId -> 经纬度 |
👉 支持:
- 附近商铺查询
- 距离排序
5.5 秒杀系统(核心🔥)
key:
1 | seckill:stock:{voucherId} |
数据结构:
- stock → String
- order → Set(已下单用户)
5.6 分布式锁
1 | lock:order:{userId} |
👉 用于:
- 控制一人一单
5.7 点赞功能
key:
1 | blog:liked:{blogId} |
value:
- ZSet
👉 score:
- 时间戳
👉 功能:
- 判断是否点赞
- 按时间排序点赞用户
5.8 关注关系
1 | follows:{userId} |
👉 Set结构:
1 | 当前用户关注的人 |
5.9 Feed 流(推模式)
key:
1 | feed:{userId} |
value:
- ZSet
👉 内容:
1 | blogId |
👉 实现:
- 关注的人发笔记 → 推送到粉丝 feed
5.10 签到功能(Bitmap)
1 | sign:{userId}:{yyyyMM} |
👉 Bitmap:
- 每一天一个 bit
👉 用途:
- 连续签到统计
六、线程池的使用
项目中出现的线程池总览:
| 场景 | 线程池作用 | 本质 |
|---|---|---|
| Redis Stream消费(异步秒杀下单) | 后台监听消息 | 长驻消费者线程 |
| 缓存逻辑过期(逻辑过期解决缓存击穿) | 异步缓存重建 | 后台刷新缓存 |
| RedisIdWorker压测 | 并发压测 | 压测线程池 |
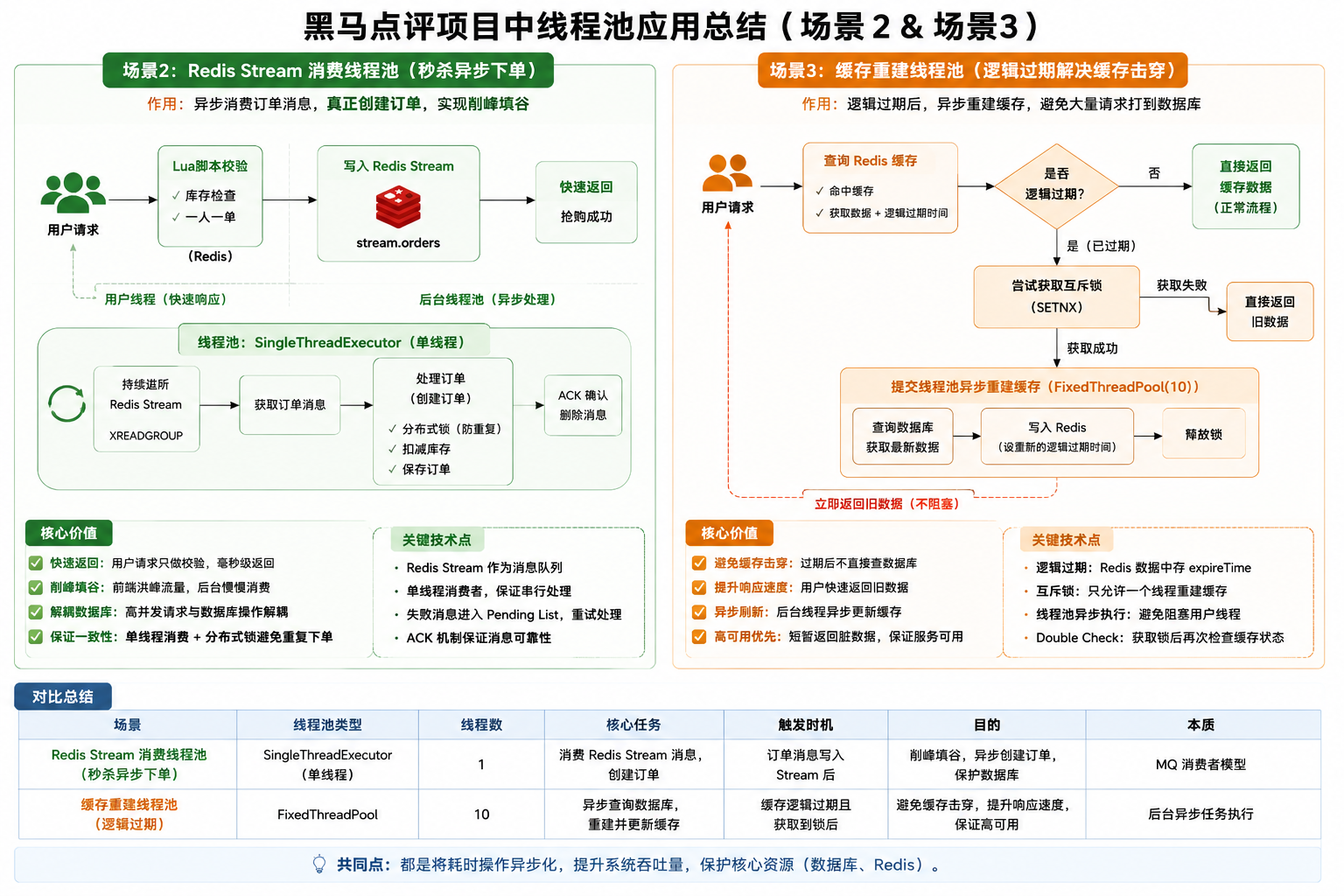
6.1 秒杀异步下单
代码:
1 | private static final ExecutorService SECKILL_ORDER_EXECUTOR = |
作用:
- 后台异步消费订单。
- 用户线程只负责抢券资格校验
- 后台线程真正创建订单
完整流程:
1 | 用户请求 |
为什么需要线程池?
- 因为数据库操作太慢
- 如果同步执行:
- RT(响应时间)变高
- Tomcat 线程被占满
- 系统吞吐下降
为什么是单线程?
- 单线程天然串行
- 避免:
- 超卖
- 并发事务问题
- 同一用户重复下单
那为什么还需要Redisson分布式锁?
- 因为项目可能是集群部署,这样做是为了防止分布式环境下重复下单
6.2 缓存重建线程池
代码:
1 | private static final ExecutorService CACHE_REBUILD_EXECUTOR = |
作用:****
- 用于缓存逻辑过期后的异步重建
- 解决缓存击穿
执行流程:
1 | 发现缓存逻辑过期 |
为什么不用当前线程重建?
- 否则用户会等待:
- 查数据库
- 写Redis
- 导致接口RT变高
为什么线程池大小是10?
- 为了限制缓存重建并发度
- 避免:
- 大量缓存同时失效
- 数据库被打崩
6.3 RedisIdWorker 压测线程池 🔥
代码:
1 | private ExecutorService es = |
作用:
- 不是业务线程池,而是并发压测线程池
- 用于测试 Redis 分布式 ID 生成器
- 是否重复:分布式ID必须全局唯一。
- 性能:高并发生成ID速度
- 线程安全:多个线程同时
nextId()是否有问题。
6.4 这些线程池有哪些问题
-
问题1:Executors 不推荐:Executors 底层:LinkedBlockingQueue 无界,可能:OOM
-
问题2:单线程吞吐有限:秒杀高峰消费能力可能不足
6.5 如果让你优化,你可以怎么答
-
自定义
ThreadPoolExecutor替代:Executors.xxx -
增加监控,监控:
- activeCount
- queueSize
- rejectCount
-
参数动态化,结合:
Nacos、Apollo动态调整线程池。 -
MQ化,进一步升级:
Kafka / RocketMQ -
多消费者,提高秒杀消费能力。
6.6 一段适合面试的总结 ⭐
黑马点评项目中线程池主要用于高并发场景下的异步化处理。
最核心的是秒杀异步下单:
用户请求先通过 Redis Lua 脚本完成库存校验和一人一单判断,然后写入 Redis >Stream,由后台线程池异步消费并创建订单,从而实现削峰填谷。
此外,在线程池还用于:
- 缓存逻辑过期后的异步缓存重建
- Redis 全局 ID 生成器的并发压测
整个项目里线程池的核心思想是:
- 异步化
- 削峰
- 限流
- 解耦
- 提升吞吐量
后续还可以进一步优化为:
- 自定义 ThreadPoolExecutor
- MQ 化
- 动态线程池
- 多消费者模型
七、系统评价指标
可以总结为:
| 维度 | 重点 |
|---|---|
| 性能 | 快不快 |
| 高并发能力 | 扛不扛得住流量 |
| 可用性 | 会不会挂 |
| 一致性 | 数据准不准 |
| 扩展性 | 后续好不好扩展 |
| 安全性 | 会不会被攻击 |
| 可维护性 | 好不好改 |
| 用户体验 | 用户感知如何 |
| 成本 | 机器/开发成本高不高 |

如果以“黑马点评”项目来评价,可以从:
“业务层 + 技术层 + 架构层”
三个角度分析。
7.1 性能指标(重点)
这是最核心的。
7.1.1 响应时间(RT)
即:一个请求从发起到返回用了多久
例如:
- 查询店铺:
- 平均 RT:20ms
- 点赞:
- 平均 RT:5ms
常见指标:
| 指标 | 含义 |
|---|---|
| Avg RT | 平均响应时间 |
| P95 | 95%请求低于该时间 |
| P99 | 99%请求低于该时间 |
例如:
P99 < 200ms 说明:99%请求都能在200ms内完成。
7.1.2 吞吐量(TPS/QPS)
即:系统每秒能处理多少请求。
例子:
- 查询店铺:
- QPS 很高
- 秒杀优惠券:
- 瞬时并发极高
比如:系统支持 1w QPS,说明系统抗压能力不错。
7.1.3 并发能力
重点看秒杀场景能否抗住:
- Redis 抗流量
- Lua 保证原子性
- MQ 削峰
- 异步下单
7.2 缓存维度(黑马点评重点)
7.2.1 缓存命中率
非常重要。
公式:缓存命中率 = 缓存命中次数 / 总请求次数
例如:95% 说明大部分请求没打到数据库。
7.2.2 数据库压力
好的系统:应该让数据库尽量少干活。
黑马点评里:
- 热点数据放 Redis
- GEO 附近店铺放 Redis
- 点赞放 Redis Set
- Feed 流放 SortedSet
都在减轻 MySQL 压力。
7.2.3 缓存问题处理能力
评价点:
| 问题 | 方案 |
|---|---|
| 缓存穿透 | 缓存空值 |
| 缓存击穿 | 互斥锁 |
| 缓存雪崩 | TTL随机化 |
7.3 高可用指标
7.3.1 系统可用性
通常用:99.9%、99.99% 表示。
例如:全年不可用时间 < 52分钟
7.3.2 故障恢复能力
比如:
- Redis 挂了怎么办
- MQ 挂了怎么办
- 服务宕机怎么办
黑马点评中:
- Redis 持久化
- Redis 主从
- Sentinel
- MQ 异步解耦
都属于高可用设计。
7.4 一致性指标
尤其是秒杀场景
核心问题:
7.4.1 超卖
黑马点评:
- Redis预扣库存
- Lua原子判断
- 数据库乐观锁兜底
这是:**“最终一致性 + 双保险”**设计。
7.4.2 重复下单
使用:用户ID + 优惠券ID做唯一约束,这是典型幂等设计。
7.5 扩展性指标
重点看:
7.5.1 能否水平扩展
例如:
- Nginx 负载均衡
- 多实例部署
- Redis 集群
- MySQL 分库分表
7.5.2 是否解耦
黑马点评:
- 秒杀异步化
- MQ 削峰
都是:**“降低系统耦合”**的典型设计。
7.6 稳定性指标
7.6.1 是否存在单点故障
比如:
- 单 Redis
- 单 MySQL
都是危险点。
7.6.2 限流降级熔断
高并发系统必须考虑。
例如:
- Sentinel 限流
- 服务降级
- 熔断保护
7.7 安全性指标
比如黑马点评中的登录:
- Redis 短信验证码
- Token 登录
- 拦截器鉴权
常见安全问题:
| 问题 | 防护 |
|---|---|
| SQL 注入 | MyBatis #{} |
| XSS | 输入过滤 |
| CSRF | Token |
| 刷接口 | 限流 |
7.8 可维护性指标
优秀系统:不只是“能跑”,而是“好维护”。
重点:
| 指标 | 举例 |
|---|---|
| 代码分层 | Controller/Service/DAO |
| 日志完善 | traceId |
| 监控 | Prometheus |
| 配置中心 | Nacos |
| 自动部署 | Docker/Jenkins |
7.9 总结
不要只说:
“系统性能很好”
而是:
1 | 我会从性能、高可用、一致性、扩展性几个维度评价系统。 |