RAG 实战
RAG(Retrieval-Augmented Generation)是一种结合检索和生成的技术,能够提升语言模型在特定领域的表现。本文将通过构建一个知识库 Agent 的实战案例,学习 RAG 的实现方法以及实现中的问题和解决方案。
一、知识库 Agent 的核心目标
知识库 Agent 的核心目标是作为团队知识管理和 AI 应用的基础设施 ,通过自动化流程,将我们日常积累的文档(比如 PDF、Markdown、技术手册、告警处理记录、历史工单等),转化为可被 AI 高效检索的向量资产。
二、RAG 全流程解析
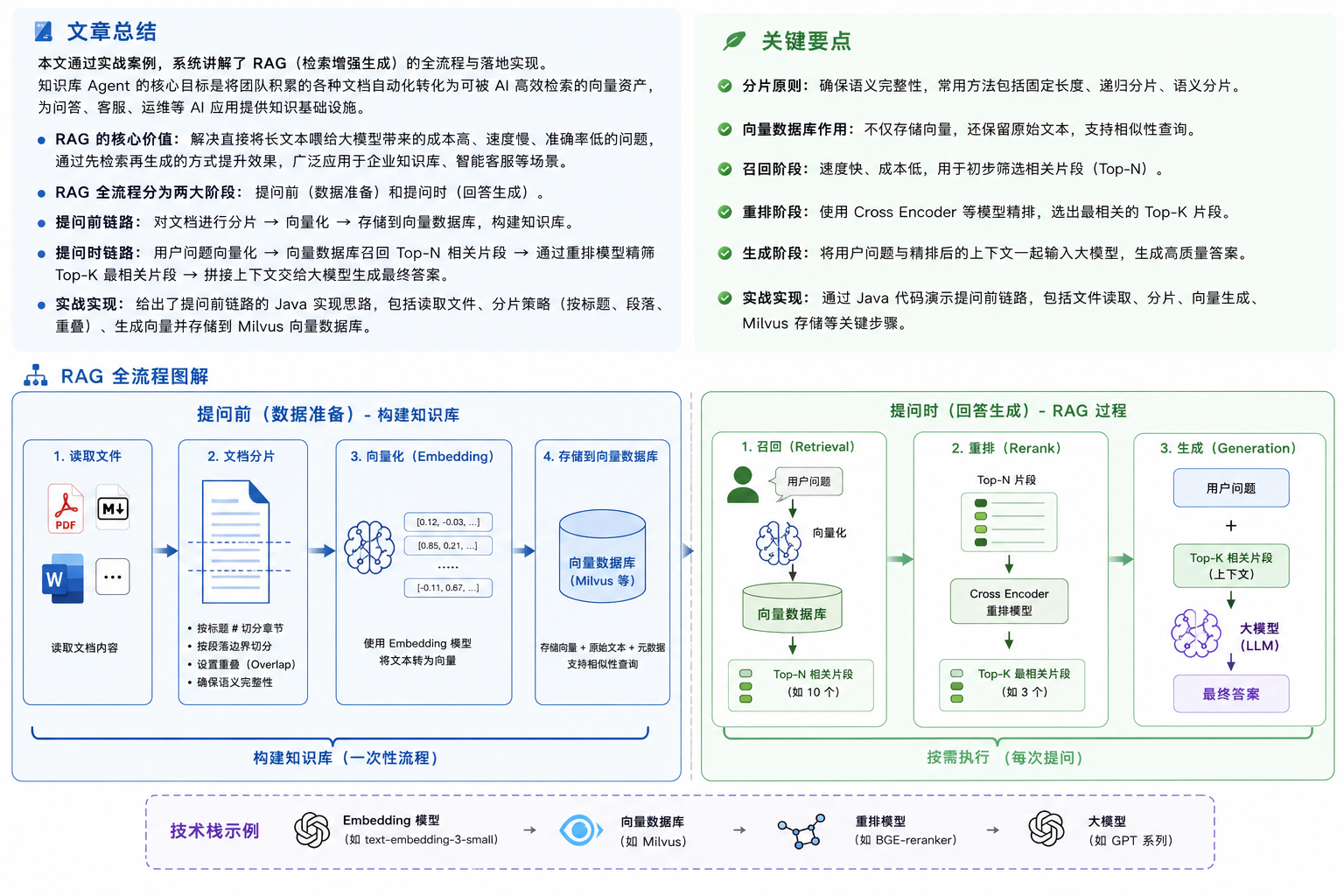
知识库 Agent 本质是就是 RAG 的过程 。RAG(检索增强生成)是构建智能客服、企业知识库、产品问答助手的核心技术。当你需要让 AI 回答特定领域问题(如公司产品手册、内部文档)时,直接将长文本发送给模型,会受限于模型的上下文窗口大小,导致成本高、速度慢、准确率低。RAG 通过先检索相关内容再生成答案的方式,完美解决了这些问题,广泛应用于企业知识管理、智能客服等场景。在对话 Agent 和运维 Agent 里,都会使用到 RAG。
1.1 核心流程
RAG 的核心流程可以分为以下几个步骤:
- 提问前(数据准备):分片 -> embedding -> 存储
- 提问时(回答生成):召回 -> 重排 -> 生成
1.2 提问前链路
- 分片:将原始文档切割为多个语义完整的片段
- 索引:
- 用 embedding 模型将每个片段转化为向量
- 将向量存储在向量数据库中(如 Pinecone、Weaviate、Milvus 等)
- 完成后,知识库构建完成,等待提问
1.2.1 分片
分片是将完整文档切割成多个语义完整的片段,常用的方法有:
- 固定长度分片:每个片段包含固定数量的字符或单词
- 递归分片:优先按段落、句子等语义边界分片,剩余部分再按固定长度分片
- 语义分片:按语义边界分片
核心原则:确保每个片段的语义完整性
1.2.2 索引
索引是将分片后的文本转化为向量并存储的过程,主要步骤包括:
- 使用 embedding 模型(如 OpenAI 的 text-embedding-3-small、text-embedding-3-large)将每个片段转化为向量
- 将向量存储在向量数据库中,常用的数据库有 Pinecone、Weaviate、Milvus 等
向量数据库不仅存储向量,还保留原始文本,因为最终生成答案需要的是文本内容,向量只是用于相似度计算。
向量数据库核心作用:
1.3 提问时链路
- 召回:用户问题 -> Embedding -> 向量 -> 向量数据库 -> Top-N 相关文本
- 重排:Top-N 相关文本 -> Cross Encoder模型 -> Top-K 最相关文本
- 生成:用户问题 + Top-K 相关文本 -> 大模型 -> 最终答案
1.3.1 召回
召回是根据用户问题检索相关文本的过程,主要步骤包括:
- 将用户问题转化为向量
- 使用向量数据库进行相似度查询,返回 Top-N 相关文本
- 特点:速度快、成本低,但准确率有限,适合初步筛选
1.3.2 重排
召回的10个片段可能仍有冗余或相关性不足,需要进一步精筛:
- 使用专门计算文本对相似度的模型,逐对计算用户问题与每个召回片段的语义相关性。
- 从 N 个片段中选出 Top K(如3个)最相关的片段。
三、实战案例:构建一个知识库 Agent
我们将通过一个实战案例,构建一个知识库 Agent,来演示 RAG 的全流程实现。
3.1 提问前链路实现
流程梳理:
- 读取文件
- 切分文件
- 索引(Embedding 和存储)
3.1.1 读取文件
我们直接传入文件路径 path,调用 Files.readString 读取文件内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
String content = Files.readString(Path
public void indexSingleFile(String filePath) throws Exception {
Path path = Paths.get(filePath).normalize();
File file = path.toFile();
if (!file.exists() || !file.isFile()) {
throw new FileNotFoundException("文件不存在或不是一个有效的文件: " + filePath);
}
String content = Files.readString(Path.of(filePath));
logger.info("从 {} 中读取文件内容成功,长度:{} 字符", path, content.length());
deleteExistingData(path.toString());
List<DocumentChunk> chunks = chunkService.chunkDocument(content, path.toString());
logger.info("文档分片完成,生成了 {} 个片段", chunks.size());
for (int i = 0; i < chunks.size(); i++) {
DocumentChunk chunk = chunks.get(i);
try {
List<Float> vector = embeddingService.generateEmbedding(chunk.getContent());
Map<String, Object> metadata = buildMetadata(path.toString(), chunk, chunk.size());
insertToMilvus(chunk.getContent(), vector, metadata, chunk.getChunkIndex());
logger.info("✓ 分片 {}/{} 索引成功", i + 1, chunks.size());
} catch (Exception e) {
logger.error("✗ 分片 {}/{} 索引失败", i + 1, chunks.size(), e);
throw new RuntimeException("分片索引失败: " + e.getMessage(), e);
}
}
logger.info("文件索引完成: {}, 共 {} 个分片", filePath, chunks.size());
}
|
3.1.2 文件分片
- 第一按照 Markdown 的标题
# 切分,将文档按照标题分割成多个章节 Section
- 第二层对每个章节进行分配,如果章节小于 MaxSize,则直接将这个章节作为一个分片
- 如果章节大于 MaxSize,则对段落边界进行切分
- 对于对段落边界进行切分的地方,还会根据 Overlap,实现段落间内容重叠,来保持段落之间的上下文语义连贯
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
List<DocumentChunk> chunks = chunkService.chunkDocument(content, path.toString());
logger.info("文档分片完成: {} -> {} 个分片", filePath, chunks.size());
public List<DocumentChunk> chunkDocument(String content, String filePath) {
List<DocumentChunk> chunks = new ArrayList<>();
if (content == null || content.isEmpty()) {
logger.warn("文档内容为空: {}", filePath);
return chunks;
}
List<Section> sections = splitByHeadings(content);
int globalChunkIndex = 0;
for (Section section : sections) {
List<DocumentChunk> sectionChunks = chunkSection(section, globalChunkIndex);
chunks.addAll(sectionChunks);
globalChunkIndex += sectionChunks.size();
}
logger.info("文档分片完成: {} -> {} 个分片", filePath, chunks.size());
return chunks;
}
private List<DocumentChunk> chunkSection(Section section, int startChunkIndex) {
List<DocumentChunk> chunks = new ArrayList<>();
String content = section.content;
String title = section.title;
if (content.length() <= chunkConfig.getMaxSize()) {
DocumentChunk chunk = new DocumentChunk(
content,
section.startIndex,
section.startIndex + content.length(),
startChunkIndex
);
chunk.setTitle(title);
chunks.add(chunk);
return chunks;
}
List<String> paragraphs = splitByParagraphs(content);
StringBuilder currentChunk = new StringBuilder();
int currentStartIndex = section.startIndex;
int chunkIndex = startChunkIndex;
for (String paragraph : paragraphs) {
if (currentChunk.length() > 0 &&
currentChunk.length() + paragraph.length() > chunkConfig.getMaxSize()) {
String chunkContent = currentChunk.toString().trim();
DocumentChunk chunk = new DocumentChunk(
chunkContent,
currentStartIndex,
currentStartIndex + chunkContent.length(),
chunkIndex++
);
chunk.setTitle(title);
chunks.add(chunk);
String overlap = getOverlapText(chunkContent);
currentChunk = new StringBuilder(overlap);
currentStartIndex = currentStartIndex + chunkContent.length() - overlap.length();
}
}
return chunks;
}
|
3.1.3 索引
- 首先对所有分片进行向量化,获取向量数组
- 构造符合 milvus 表记录的结构体。id、content、vector、metadata
- 构造完记录后,插入到数据库中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
for (int i = 0; i < chunks.size(); i++) {
DocumentChunk chunk = chunks.get(i);
try {
List<Float> vector = embeddingService.generateEmbedding(chunk.getContent());
Map<String, Object> metadata = buildMetadata(path.toString(), chunk, chunks.size());
insertToMilvus(chunk.getContent(), vector, metadata, chunk.getChunkIndex());
logger.info("✓ 分片 {}/{} 索引成功", i + 1, chunks.size());
}
}
public List<Float> generateEmbedding(String content) {
try {
TextEmbeddingParam param = TextEmbeddingParam
.builder()
.model(model)
.texts(Collections.singletonList(content))
.build();
TextEmbeddingResult result = textEmbedding.call(param);
List<Float> floatEmbedding = getFloats(result);
return floatEmbedding;
}
}
private void insertToMilvus(String content, List<Float> vector,
Map<String, Object> metadata, int chunkIndex) throws Exception {
try {
String source = (String) metadata.get("_source");
String id = UUID.nameUUIDFromBytes((source + "_" + chunkIndex).getBytes()).toString();
List<InsertParam.Field> fields = new ArrayList<>();
fields.add(new InsertParam.Field("id", Collections.singletonList(id)));
fields.add(new InsertParam.Field("content", Collections.singletonList(content)));
fields.add(new InsertParam.Field("vector", Collections.singletonList(vector)));
com.google.gson.Gson gson = new com.google.gson.Gson();
com.google.gson.JsonObject metadataJson = gson.toJsonTree(metadata).getAsJsonObject();
fields.add(new InsertParam.Field("metadata", Collections.singletonList(metadataJson)));
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(MilvusConstants.MILVUS_COLLECTION_NAME)
.withFields(fields)
.build();
R<MutationResult> insertResponse = milvusClient.insert(insertParam);
if (insertResponse.getStatus() != 0) {
throw new RuntimeException("插入向量失败: " + insertResponse.getMessage());
}
logger.debug("向量插入成功: id={}, source={}, chunk={}", id, source, chunkIndex);
} catch (Exception e) {
logger.error("插入向量到 Milvus 失败", e);
throw e;
}
}
|
3.2 提问时链路实现
3.2.1 召回
- 将查询文本向量化
- 相似度查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
public List<SearchResult> searchSimilarDocuments(String query, int topK) {
try {
logger.info("开始搜索相似文档, 查询: {}, topK: {}", query, topK);
List<Float> queryVector = embeddingService.generateQueryVector(query);
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName(MilvusConstants.MILVUS_COLLECTION_NAME)
.withVectorFieldName("vector")
.withVectors(Collections.singletonList(queryVector))
.withTopK(topK)
.withMetricType(io.milvus.param.MetricType.L2)
.withOutFields(List.of("id", "content", "metadata"))
.withParams("{\"nprobe\":10}")
.build();
R<SearchResults> searchResponse = milvusClient.search(searchParam);
SearchResultsWrapper wrapper = new SearchResultsWrapper(searchResponse.getData().getResults());
List<SearchResult> results = new ArrayList<>();
for (int i = 0; i < wrapper.getRowRecords(0).size(); i++) {
SearchResult result = new SearchResult();
result.setId((String) wrapper.getIDScore(0).get(i).get("id"));
result.setContent((String) wrapper.getFieldData("content", 0).get(i));
result.setScore(wrapper.getIDScore(0).get(i).getScore());
Object metadataObj = wrapper.getFieldData("metadata", 0).get(i);
if (metadataObj != null) {
result.setMetadata(metadataObj.toString());
}
results.add(result);
}
return results;
}
}
|
首先我们对问题进行向量化,按照Spring AI 的sdk要求,拼接请求参数,然后调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public List<Float> generateEmbedding(String content) {
try {
TextEmbeddingParam param = TextEmbeddingParam
.builder()
.model(model)
.texts(Collections.singletonList(content))
.build();
TextEmbeddingResult result = textEmbedding.call(param);
List<Float> floatEmbedding = getFloats(result);
return floatEmbedding;
}
}
|
然后我们使用Milvus的sdk,进行相似度,获取相似的向量数据
1
2
3
4
5
6
7
8
9
10
11
12
13
|
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName(MilvusConstants.MILVUS_COLLECTION_NAME)
.withVectorFieldName("vector")
.withVectors(Collections.singletonList(queryVector))
.withTopK(topK)
.withMetricType(io.milvus.param.MetricType.L2)
.withOutFields(List.of("id", "content", "metadata"))
.withParams("{\"nprobe\":10}")
.build();
R<SearchResults> searchResponse = milvusClient.search(searchParam);
|
总结:对问题先进行向量化,然后根据向量,调用数据库的向量查询接口进行查询。
四、RAG 实战中的问题和解决方案
4.1 检索层问题(最核心)
4.1.1 检索不准(Top-K 全是“看起来相关但没用”的内容)
常见原因
- chunk 切分不合理(太大 / 太碎)
- embedding 模型语义能力弱
- query 和文档分布不一致(语言/表达差异)
4.1.2 解决方案
- 优化 Chunking(优先级最高)
- 300–800 tokens
- overlap 10–20%
- 按“语义块”切(而不是固定长度)
- Query Rewrite / Expansion
1
2
3
4
5
| 用户问:怎么解决超卖
→ 改写:
- 分布式锁
- Redis Lua
- 乐观锁
|
👉 实战中通常用 LLM 做:
- multi-query(生成3~5个query并检索)
- Hybrid Search(强烈推荐)
👉 解决 embedding 漏掉关键词的问题
- 引入 Re-ranker(质变)🔥
流程:
1
| Top-K → Cross Encoder → 排序
|
效果:
4.2 生成层问题(LLM阶段)
4.2.1 幻觉(Hallucination)
👉 模型开始“编”
解决方案
- 强约束 Prompt
1
2
| 只允许基于提供的Context回答,
如果找不到答案就说“不知道”
|
- 强制引用来源
- 限制上下文
4.2.2 上下文污染(Context Pollution)
👉 检索回来很多“半相关内容”,干扰模型
解决方案
- rerank(必须有)
- chunk 去重(相似度过滤)
- 按相关性截断
4.3 数据层问题(80%的人忽略)
4.3.1 数据质量差
👉 垃圾数据 → 再好的模型也没用
表现
解决方案
- 数据清洗 pipeline
- 去重(hash / embedding)
- 标记时间(time-aware RAG)
4.3.2 文档结构丢失
👉 比如:
解决方案
1
2
3
4
5
| {
"title": "...",
"section": "...",
"page": 3
}
|
4.4 系统层问题(工程化)
4.4.1 延迟高(Latency)
👉 用户体验直接崩
来源
- embedding
- 向量检索
- rerank
- LLM
解决方案
- embedding 缓存
- ANN(近似最近邻,如 FAISS IVF)
- 限制 Top-K(如 5)
- 小模型 rerank
- streaming 输出
五、总结